
🔧 Los 7 parámetros que controlan cómo responde un modelo de IA

En el mundo de la inteligencia artificial generativa, entender cómo “piensa” un modelo de lenguaje (LLM) es clave para aprovechar su poder.
¿Te has preguntado por qué a veces ChatGPT responde de forma precisa y otras veces se pone más creativo o divaga un poco?
La respuesta está en los parámetros de generación.
Hoy en SAB-IA, te explicamos los 7 parámetros fundamentales que puedes ajustar para controlar cómo responde un modelo de lenguaje, de forma simple y en español 👇
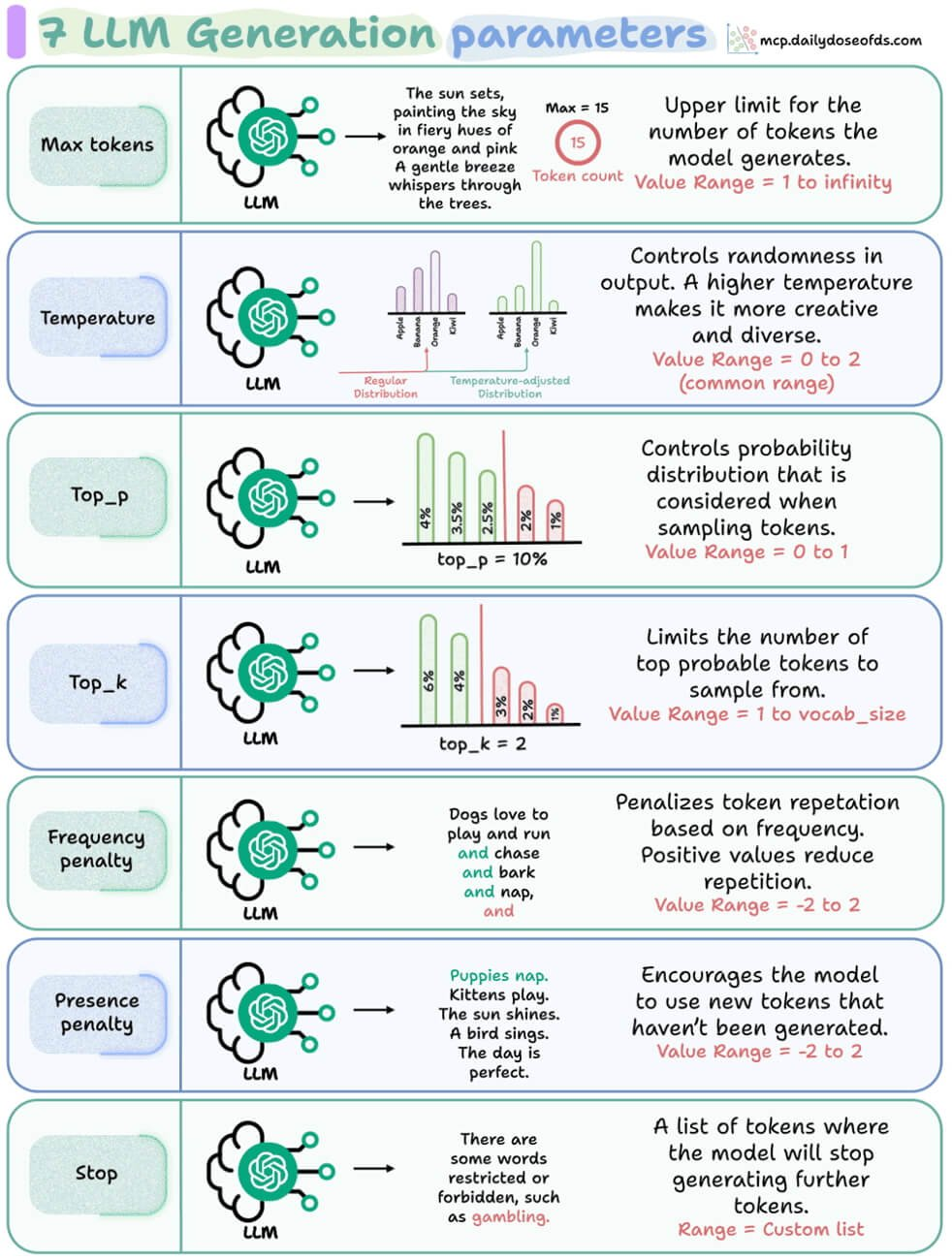
1️⃣ Max Tokens
🔹 Qué hace: Define cuántas palabras (tokens) puede generar el modelo.
🔹 Por qué importa: Si lo dejas muy corto, cortará las respuestas; si lo pones muy largo, puede extenderse de más.
🔹 Rango común: 1 hasta el infinito.
💡 Ejemplo: Si limitas a 15 tokens, obtendrás algo breve como una frase poética o una oración.
2️⃣ Temperature
🔹 Qué hace: Controla la creatividad del modelo.
🔹 Por qué importa: Una temperatura baja (0–0.3) produce respuestas más predecibles; una alta (0.7–1.5) genera respuestas más variadas e imaginativas.
🔹 Rango común: 0 a 2.
💡 Pro tip: Usa temperatura alta para brainstorming o escritura creativa, y baja para tareas técnicas o precisas.
3️⃣ Top-p (Nucleus Sampling)
🔹 Qué hace: Limita el rango de probabilidades de palabras que el modelo considera.
🔹 Por qué importa: En lugar de considerar todas las opciones, se queda con las que suman hasta cierto porcentaje de probabilidad.
🔹 Rango común: 0 a 1.
💡 Ejemplo: Con top_p = 0.1, el modelo elige entre el 10% de las palabras más probables.
4️⃣ Top-k
🔹 Qué hace: Define cuántas palabras candidatas puede elegir el modelo.
🔹 Por qué importa: Un número pequeño genera respuestas más controladas, uno alto da más libertad.
🔹 Rango común: 1 hasta el tamaño del vocabulario.
💡 Ejemplo: Con top_k = 2, el modelo solo elige entre las 2 palabras más probables para cada paso.
5️⃣ Frequency Penalty
🔹 Qué hace: Penaliza la repetición.
🔹 Por qué importa: Si el modelo empieza a repetir frases, este parámetro ayuda a hacerlo más variado.
🔹 Rango común: -2 a 2.
💡 Ejemplo: Un valor alto evita que repita estructuras como “y corren, y saltan, y juegan…”
6️⃣ Presence Penalty
🔹 Qué hace: Incentiva el uso de nuevas palabras o ideas.
🔹 Por qué importa: Perfecto si quieres que el modelo explore nuevos temas o evite redundancias.
🔹 Rango común: -2 a 2.
💡 Ejemplo: Ayuda a que la respuesta incluya conceptos que aún no se han mencionado.
7️⃣ Stop Sequences
🔹 Qué hace: Define en qué punto debe dejar de generar texto.
🔹 Por qué importa: Puedes usarlo para cortar respuestas o delimitar estructuras (por ejemplo, detenerse al final de una etiqueta HTML).
🔹 Rango común: Lista personalizada de tokens.
💡 Ejemplo: ["END", "</s>", "\n\n"] puede usarse para detener una generación al final de un bloque.
💬 En resumen
Estos parámetros son como los controles de una consola creativa: puedes ajustar cada uno según el tipo de tarea que tengas.
- ¿Quieres precisión? ➜ baja temperatura, bajo top-p.
- ¿Buscas creatividad? ➜ sube la temperatura y el top-p.
- ¿Necesitas respuestas concisas? ➜ limita los tokens y define un stop claro.
Conocerlos te permite convertirte en un verdadero “IA Tuner”: alguien que no solo usa modelos de lenguaje, sino que los moldea para obtener exactamente lo que necesita.
🧠 En SAB-IA creemos que aprender estos fundamentos es el primer paso para dominar la inteligencia artificial de manera práctica y profesional.
¿Quieres seguir aprendiendo cómo aplicar IA en tu trabajo o negocio?


