
Compresión Sin Pérdida Diseñada para IA

ZipNN, la nueva biblioteca de compresión de código abierto de IBM, puede reducir los costos de almacenamiento de IA en un tercio y acelerar las transferencias hasta en un 150% — sin pérdida de rendimiento.
Cuando compartes fotos o música en línea, seguramente has manejado un archivo JPG o MP3. Ambos formatos de compresión reducen el tamaño de los archivos al eliminar detalles percibidos como menos importantes para el ojo o el oído. La compresión ZIP, por el contrario, agrupa información redundante para que los archivos puedan restaurarse a su tamaño y calidad originales cuando se descomprimen.
Debido a su naturaleza "sin pérdidas", ZIP se utiliza a menudo para archivar documentos. Hasta ahora, no se consideraba adecuado para comprimir modelos de IA con miles de millones de pesos numéricos aparentemente aleatorios. Sin embargo, al examinar más de cerca los pesos del modelo, los investigadores descubrieron patrones que podrían aprovecharse para reducir tanto el tamaño del modelo como las limitaciones de ancho de banda.
En colaboración con la Universidad de Boston, Dartmouth, MIT y la Universidad de Tel Aviv, los investigadores de IBM crearon ZipNN, una biblioteca de código abierto que encuentra automáticamente el mejor algoritmo de compresión para un modelo dado según sus propiedades. ZipNN puede reducir los formatos LLM populares en un tercio y comprimir y descomprimir modelos 1.5 veces más rápido que la siguiente mejor técnica. El equipo presentó sus hallazgos en un nuevo estudio que se presentará en la próxima conferencia IEEE Cloud 2025.
“Nuestro método puede reducir los costos de almacenamiento y transferencia de IA con prácticamente ninguna desventaja”, dijo Moshik Hershcovitch, un investigador de IBM centrado en IA e infraestructura en la nube. “Cuando descomprimes el archivo, vuelve a su estado original. No pierdes nada.”
Compresión sin pérdida de calidad
Existen varias formas de reducir el tamaño de un modelo de IA para disminuir el costo de enviarlo a través de una red. El modelo puede ser podado para eliminar pesos innecesarios. Su precisión, o nivel de exactitud, también puede reducirse mediante cuantización. O puede destilarse en una versión más compacta de sí mismo mediante un proceso de enseñanza-aprendizaje. Los tres métodos de compresión pueden aumentar las velocidades de inferencia de IA, pero como eliminan información del modelo, a veces la calidad se ve afectada.
La compresión sin pérdidas, por el contrario, elimina temporalmente información repetitiva y luego la restitute; la compresión LZ reemplaza largas secuencias con punteros cortos, mientras que la codificación de entropía reemplaza elementos utilizados frecuentemente con representaciones abreviadas.
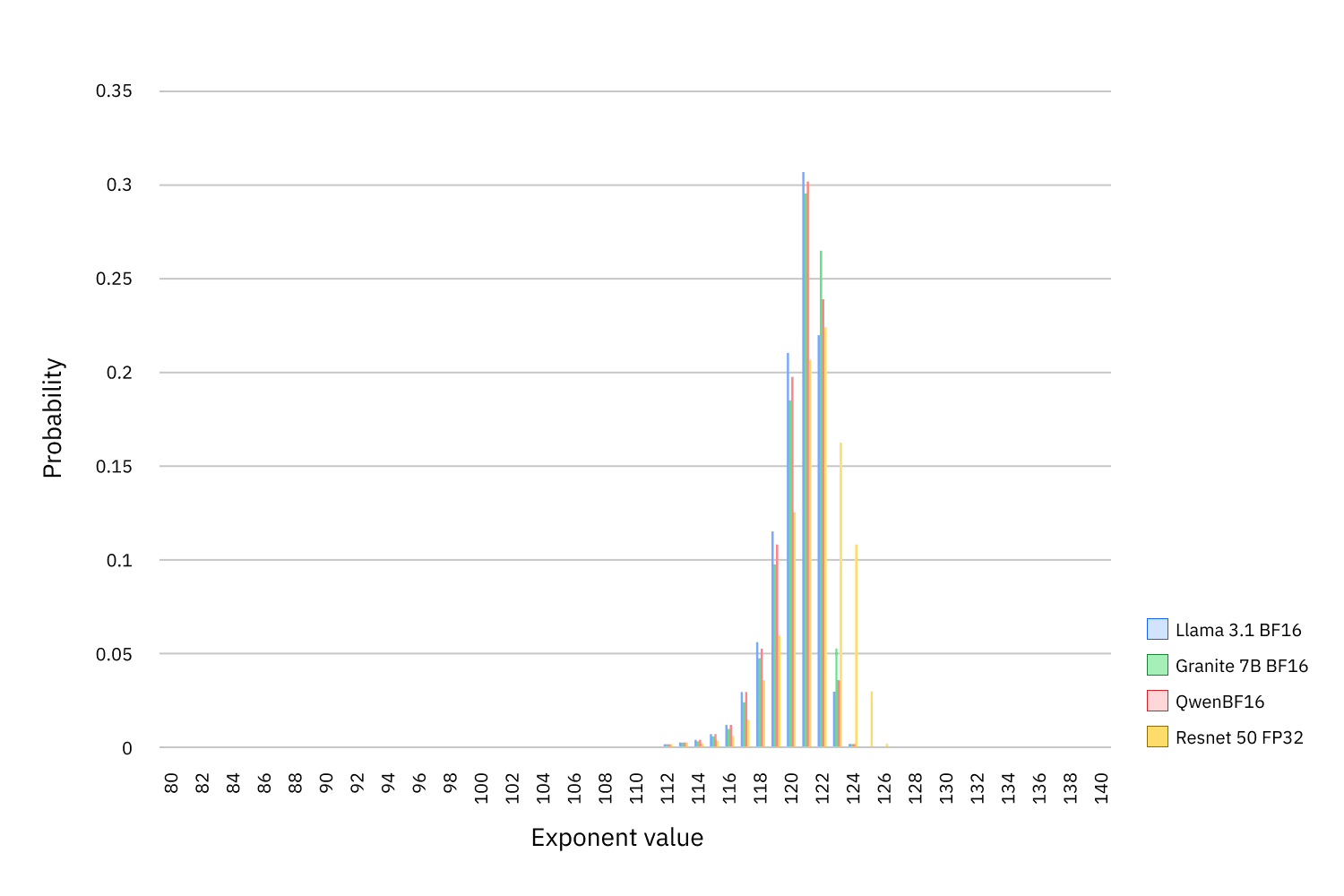
La información en los modelos de IA se almacena como pesos numéricos, que generalmente se representan mediante un número en punto flotante entre 0 y 1. Cada número tiene tres partes: un signo, un exponente y una fracción. Mientras que el signo y la fracción son típicamente aleatorios, los investigadores de IBM descubrieron que los exponentes son altamente sesgados. De 256 valores posibles, los mismos 12 aparecen el 99.9% del tiempo.
El equipo detrás de ZipNN se dio cuenta de que podía utilizar una forma de codificación de entropía para explotar este desequilibrio. Separaron los exponentes de cada número en punto flotante de sus signos y fracciones aleatorios, y luego utilizaron la codificación de Huffman para comprimir los exponentes.
La cantidad que ZipNN puede reducir el tamaño de un modelo de IA depende del formato de bits del modelo y de cuánto espacio ocupan los exponentes. Por comparación, los exponentes ocupan la mitad de los bits en los modelos más nuevos con formato BF16, pero solo un cuarto de los bits en los modelos más antiguos con formato FP32.
No sorprende que ZipNN funcionara mejor con modelos BF16 en las series de modelos Meta Llama, IBM Granite y Mistral, reduciendo su tamaño en un 33%, una mejora del 11% sobre el siguiente mejor método, Zstandard (zstd) de Meta. Las velocidades de compresión y descompresión también mejoraron, mostrando los modelos Llama 3.1 un aumento promedio del 62% sobre zstd.
Los ahorros fueron menores, pero aún significativos, para los modelos en formato FP32. ZipNN redujo su tamaño en un 17%, una mejora del 8% sobre zstd, mientras también mejoraba las velocidades de transferencia.
Los investigadores descubrieron que podían obtener una relación de compresión aún mayor en algunos modelos populares que no habían sido ajustados al aprovechar las redundancias en las fracciones de cada peso. Dividiendo cada fracción en tres flujos, en lo que llaman "agrupación de bytes", los investigadores redujeron el tamaño del modelo xlm-RoBERTa de Meta a menos de la mitad.
La agrupación de bytes fue recientemente implementada por Hugging Face en su nuevo backend de almacenamiento. En una publicación de blog anunciando el movimiento en febrero, un autor notó en la sección de comentarios que su uso de “agrupación de bytes inspirada por ZipNN” había ahorrado aproximadamente un 20% en costos de almacenamiento.
Ahorros en el mundo real
El método ZipNN podría ahorrar tiempo y dinero a empresas y otras organizaciones que entrenan, almacenan o sirven modelos de IA a gran escala. Una implementación completa de ZipNN en Hugging Face, que atiende más de un millón de modelos por día, podría eliminar petabytes de datos de almacenamiento y exabytes de datos de redes, estiman los investigadores. También podría reducir el tiempo que los usuarios pasan subiendo y descargando modelos desde el sitio.
El almacenamiento de modelos de “checkpoint” es otro posible caso de uso. Los desarrolladores guardan cientos a miles de versiones tempranas de cada modelo de IA terminado que producen. Reducir incluso una fracción de estos modelos en borrador podría llevar a ahorros significativos. El equipo detrás de IBM Granite planea implementar pronto ZipNN para comprimir sus modelos de IA de checkpoint.
Los investigadores detrás de ZipNN también están explorando cómo integrar la biblioteca con vLLM, la plataforma de código abierto para inferencia eficiente de IA.
Imagen: Figura 2 con pie de foto:
La información en los modelos de IA se almacena como pesos numéricos, representados generalmente por un número en punto flotante entre 0 y 1. Cada número tiene tres partes: un signo, un exponente y una fracción. Mientras que el signo y la fracción son típicamente aleatorios, los investigadores recientemente descubrieron que los exponentes están altamente sesgados. De 256 valores posibles, 12 aparecen el 99.9% del tiempo.
Para más contenido especializado, suscríbete a nuestro boletín: Suscribirse al boletín



Comments ()